Stateful Assets
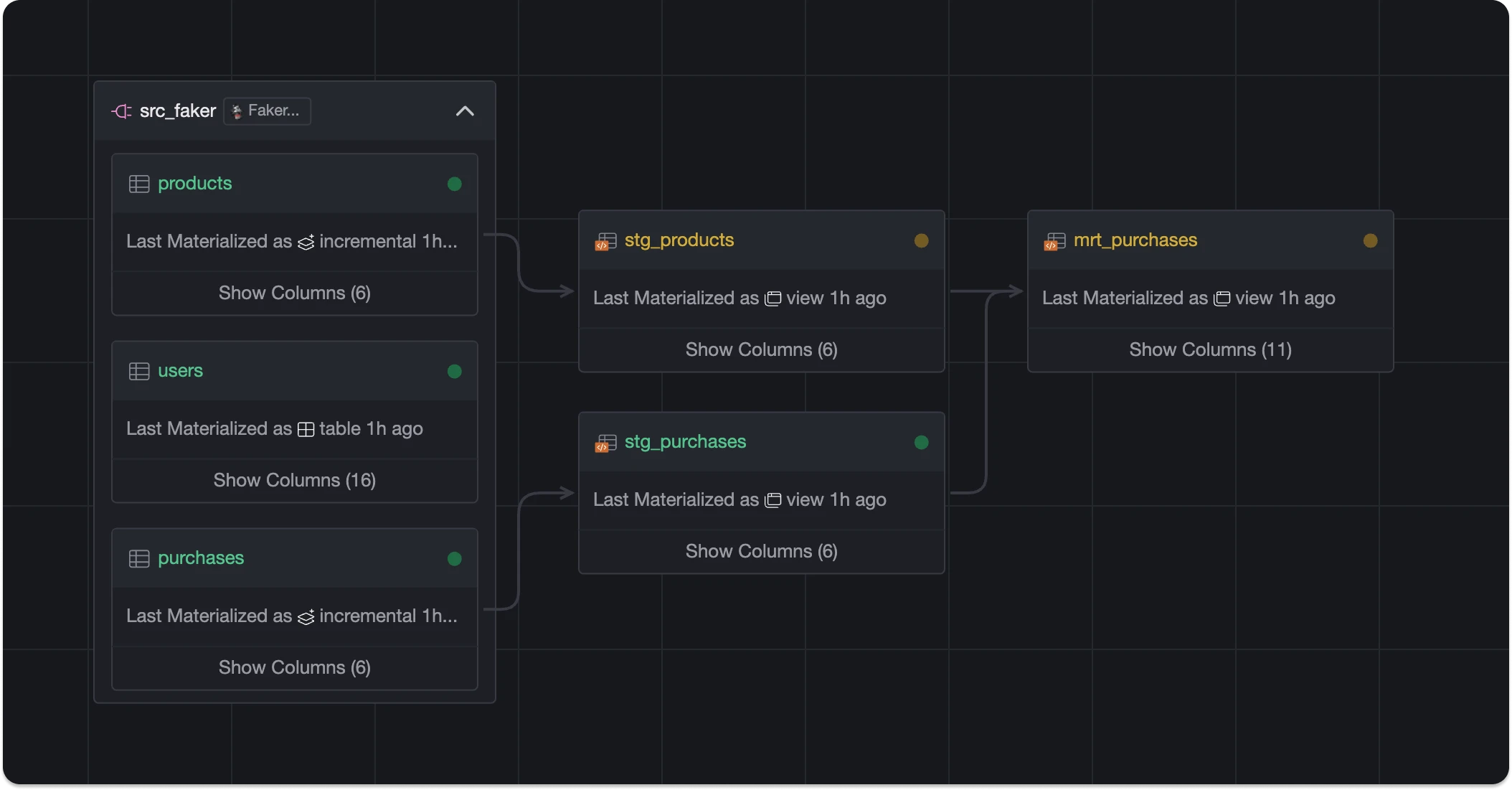
Data asset's dependencies and health status viewed in Lineage mode.
Overview
Data assets are the fundamental blocks of data pipelines. Each data asset is a set of persisted table objects that captures some understanding of the world over time, according to its definition written as code. By adding YAML configurations, we bind tests, dependencies and metadata to our asset.
As a whole, the persisted table snapshots created over time, including its methods and attributes, form a data asset.
Managing state
In the realm of data, managing state it's the primary means to understanding the ever-changing world. Every time you transform the data, apply masking policies, set permissions, or re-run a model you are inherently manipulating the state of the data asset.
You can think of a data asset, similar to a river: it changes and evolves over time due to various factors, such as new data coming in, existing data being updated or deleted, or transformations being applied upstream that have to be propagated. With each change, a new variation of the asset is created in the form of a table.
The table in your data warehouse is a snapshot in time of your data asset, representing the state of the data asset at a specific point in time. While these snapshots remain static, the actual data asset, similar to a river, continues to flow and evolve over time as new data comes in.
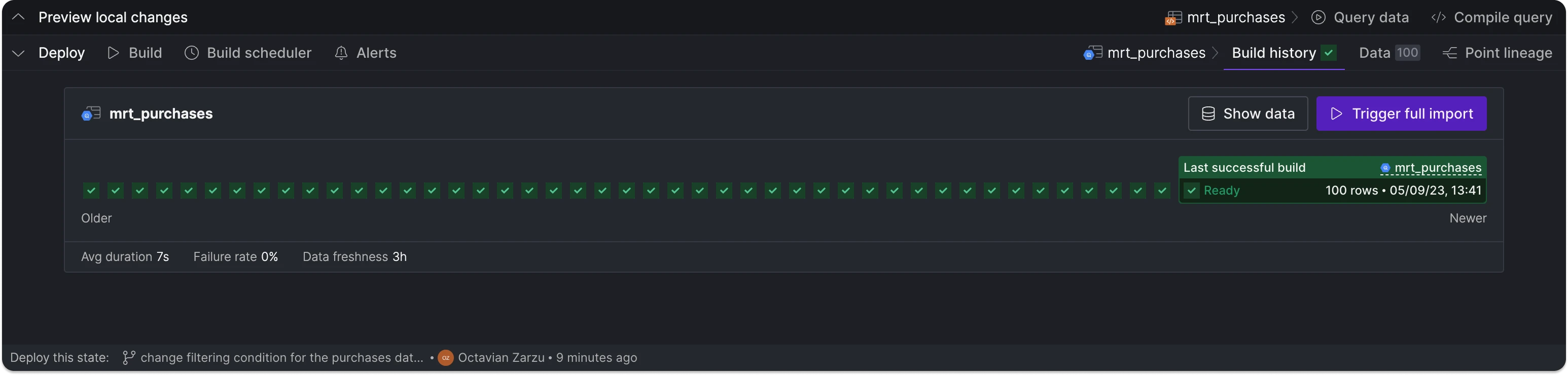
The data asset represents a collection of table snapshots over time.
If one of the builds fails — either because the asset cannot be materialized or because one of the linked tests doesn't pass — Y42 automatically rolls back to the last valid build, ensuring that users always access correct data.
To encapsulate all of these components into a single logical unit, we introduce a new stateful and declarative approach of building and managing data assets, called Stateful Data Assets.
Stateful & declarative concepts explained
Stateful is a term used to describe a system, or an object that retains information or state across interactions over time, from one operation to the next. This memory of past events can influence future operations.This is in contrast to stateless systems, which do not retain any information between interactions.
However, being stateful doesn't negate idempotency. In Y42, while a model's transformation logic is idempotent (consistently producing the same outcome regardless of how many times it's run), the model asset itself retains state, capturing its history and changes over time as new data flows in.
In the context of data engineering and pipelines, stateful refers to the fact that data assets can retain information across the different stages of the asset lifecycle, data transformations, or over time. This stateful nature of data assets means that the output at any stage of the pipeline may be influenced by the accumulated state of the data up to that point.
To give an example, consider a data asset that accumulates records over time from various sources. When new data is integrated into the asset, a stateful system remembers the prior state of the asset, runs all tests and merges the new data appropriately in. Furthermore, since the system tracks all variations of the asset, if one of the tests fails, it can fallback to the previous successful run of the asset.
Stateful approach.
In contrast, in a stateless system, every time new data is added, the system would treat the asset as entirely new, without any reference to its prior state. This means it doesn't matter how many times a model has been run before, or even if it has ever been run; every execution is treated as if it's the first. A prime example of this is dbt. When rolling back code changes in such a stateless environment, the system wouldn’t have any knowledge of how the asset was physically materialized at any previous point in time.
Stateless approach.
The declarative approach is about specifying what you want to achieve without necessarily detailing how to achieve it. You declare the desired outcomes, and the underlying system determines the steps to get there.
On the other hand, the imperative paradigm is about how you want to achieve a certain state by detailing the step-by-step process to achieve a desired outcome. As a user you have to provide direct instructions, where you specify every operation and the order in which they must be executed.
For data assets, the declarative approach translates to specifying the desired end state of the dataset, without explicitly telling the system how to get there. For instance, you might declare that you want a dataset that consolidates data from several sources, filters out irrelevant records, apply tests, and sorts the remainder by a specific criterion. That is the end state. The underlying system will then figure out the best way to materialize this request.
In the declarative approach, I want to:
- Merge data from orders and billing
- Filter last year’s orders
- Apply referential integrity to all dimension links
- Sort data to improve BI queries
- Mask sensitive data according to column values
- Grant only departments X and Y access to view data
In contrast, in an imperative approach, you'd explicitly detail that first, you merge datasets A and B, then filter records with a specific attribute, followed by sorting the resultant set.
In the imperative approach, run the following commands in order:
- Pushdown filters f1 and f2 to improve performance
- Merge A and B tables with A on the left side on cond.
- Apply the following tests: fact_dim..id:dim_dateid, ..
- Sort data by columns col_a and col_b
- Run optimization job
- ..
- Mask the following columns: col_c and col_d
- Grant select on table AB to marketing_role
Summary
In the rapidly evolving landscape of data management, the concept of Stateful Data Assets (SDA) stands out as a revolutionary approach, designed to enhance how businesses understand and interact with their data. At its core, SDA represents a cohesive collection of table objects, tests, dependencies, and metadata, which together capture a dynamic snapshot of the world as it changes over time.
By leveraging a declarative model, SDA focuses on the desired outcomes rather than the intricacies of the processes involved, simplifying data management tasks. This approach not only streamlines the materialization and maintenance of data assets within a warehouse but also ensures that each data asset retains its history and changes, enabling a more intuitive and effective way to understand and utilize data across various stages of its lifecycle.