Python actions
Sync your data pipelines with third-party sytems.
Overview
Python Actions allow you to sync your data pipelines with workflows in Asana, JIRA, Make or any tool you prefer. This feature supports a wide range of use cases, such as Reverse ETL data into Salesforce, task creation in Asana, notifications in Slack, data generation in Google Sheets, or data entry into operational databases.
Python Actions provide a Zapier or Make-like functionality, with the added benefits of having all your processing in one place, within one data lineage, and having integrated documentation, within your team's existing workflow.
Add a Python action
Press CMD / CTRL + K or click the + button to access the create new asset menu. Find Python actions under the Consume tab within this menu.
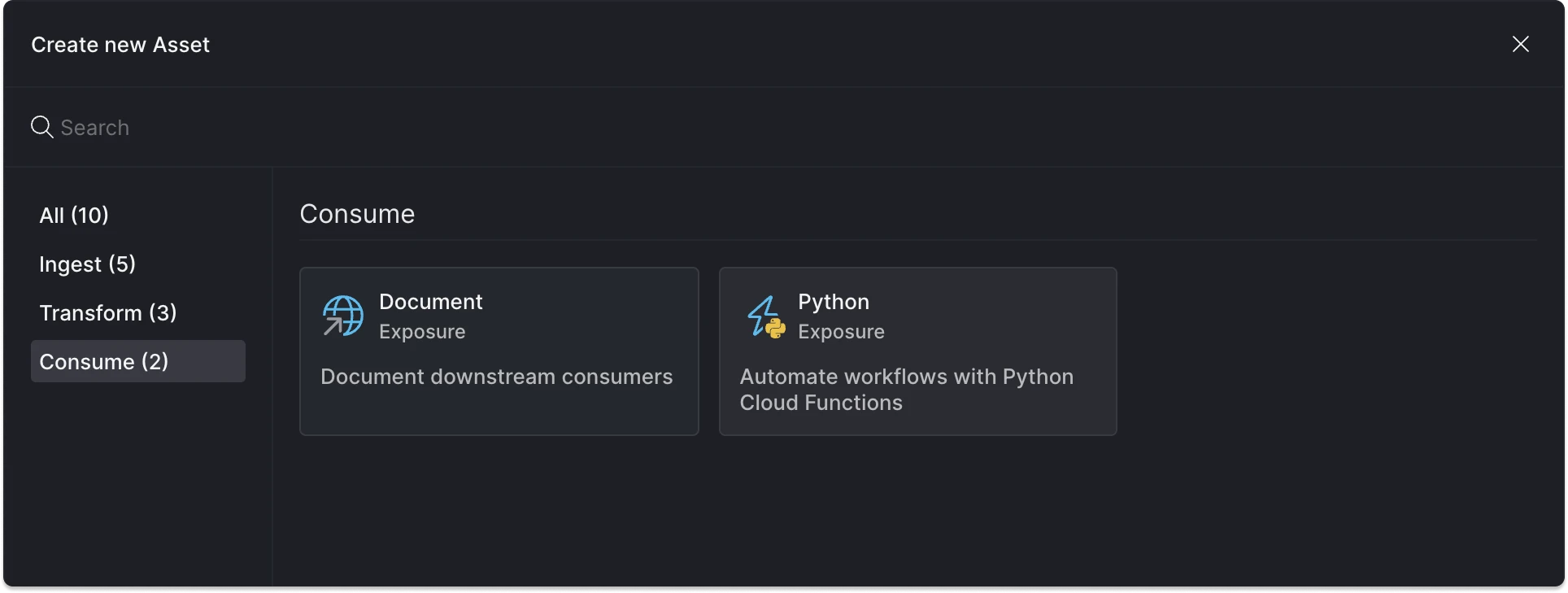
Add a Python Action asset.
To add a Python action asset, you need to configure the following:
- Script: The Python code that triggers the action in a third-party system.
- Dependencies: Define the upstream dependencies.
Script
Within your python code, you can use the @data_loader decorator to trigger actions in third party systems.
Import data_action and required modules.
Begin by importing the data_action, along with any other necessary modules to sync data externally.
Define your logic as function and apply the @data_action decorator.
Create a function that transforms the upstream data and sends it to a third party system.
[Optional] Reference secrets if needed
If needed, custom secrets can be referenced in Python scripts using the context.secrets syntax.
Dependencies
Dependencies define the upstream dependencies of your Python, helping Y42 understand how the Python asset connects with other assets in the space. It also determines when to trigger the asset and updates the lineage view with the new relationships.
Commit changes & trigger the sync
Save your changes by committing them. You can build the asset using dag selectors or via the Build history tab.
The + selector, when used in front of the asset name in the command, also triggers all upstream dependencies.
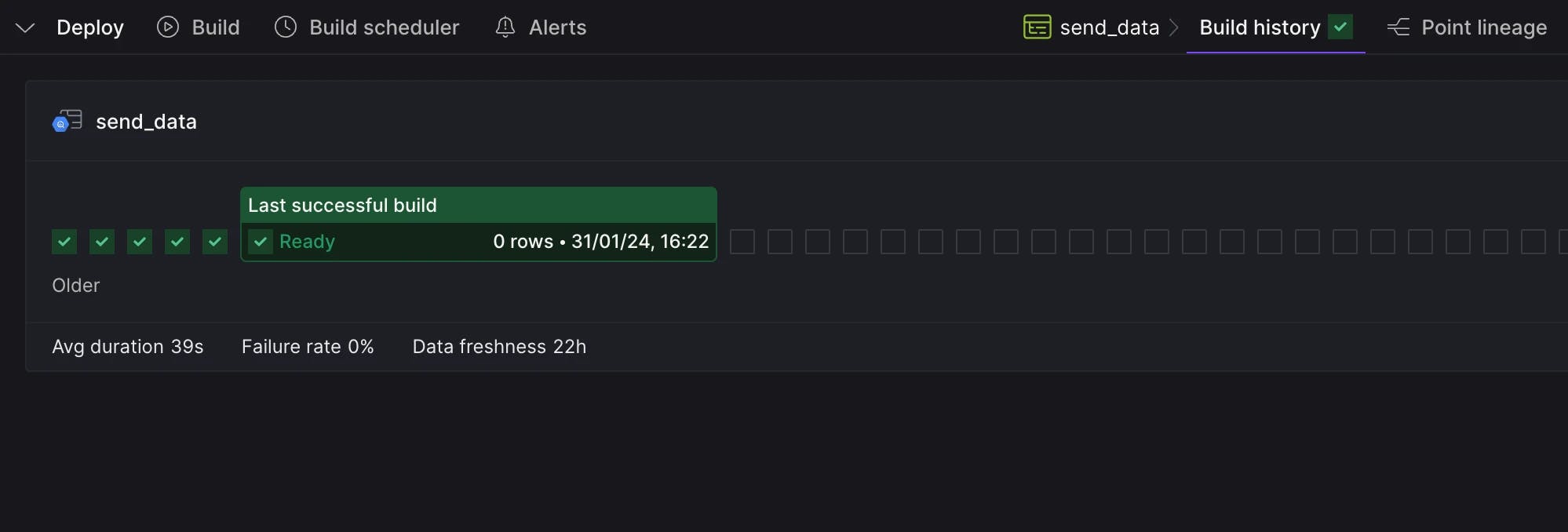
Build history tab.
Functions and dependencies management
- Multiple functions in one script: Multiple functions can be included in a single script with the
@data_loaderdecorator. Each decorated function will be triggered. - Non-decorated functions: Functions without the
@data_loaderdecorator won't trigger independently. However, they can be invoked within a decorated function. - Dependencies management: For scripts with multiple decorated functions, the combined set (union) of dependencies from all functions is displayed.
Using secrets in Python scripts
You can reference custom secrets in Python scripts using the following syntax:
_10@data_action_10def send_data(context, assets):_10 # Reference secrets if needed_10 all_secrets = context.secrets.all() # get all secrets saved within this space_10 one_secret = context.secrets.get('<SECRET_NAME>') # get the value of a specific secret saved within this space
Logging
Use the logging module (opens in a new tab) to log messages.
Example:
You can view the logs by accessing an asset's Build history and selecting the Logs tab.
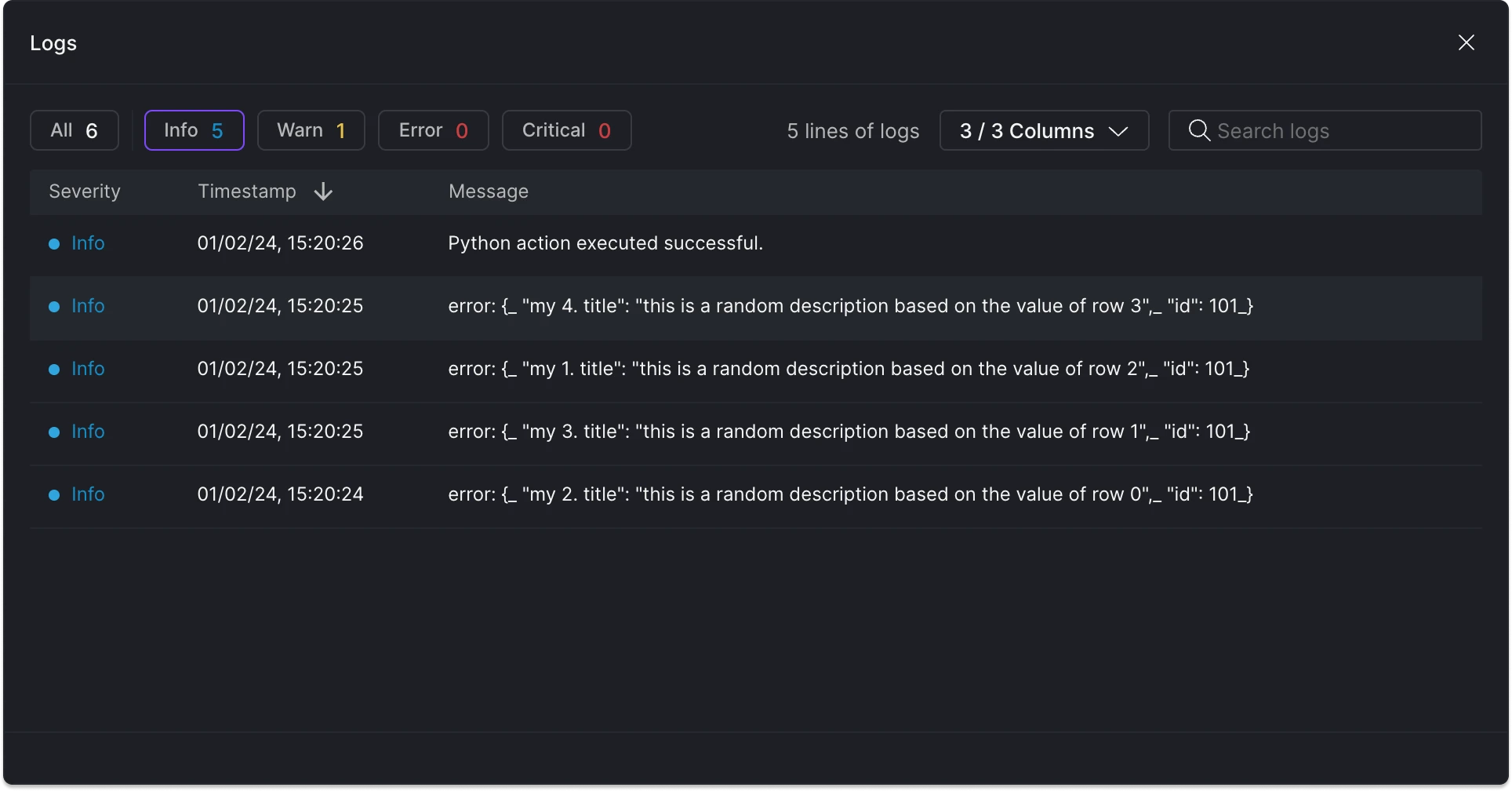
Visualize Python asset logs in the Build history tab.
To enhance the readability of logs, especially when dealing with dataframes, we recommend utilizing the dataframe to HTML function (opens in a new tab). This function converts your dataframe into an HTML table, making your logs more structured and easier to read.
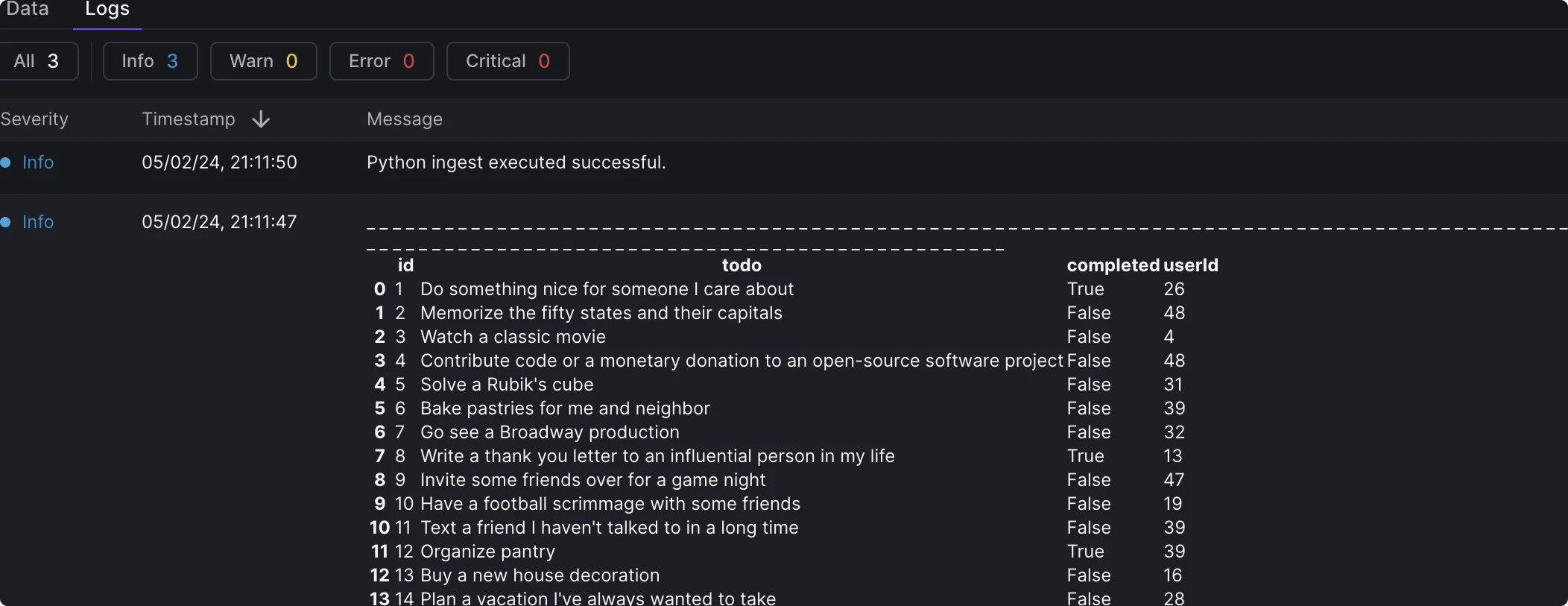
Formatted logs example.
Preview data and logs
While Python actions primarily trigger external actions, you can preview the data by optionally making the decorated function return a DataFrame.
Preview the data and view logs for each function decorated with @data_action by clicking on the "Preview" option located above the function name.
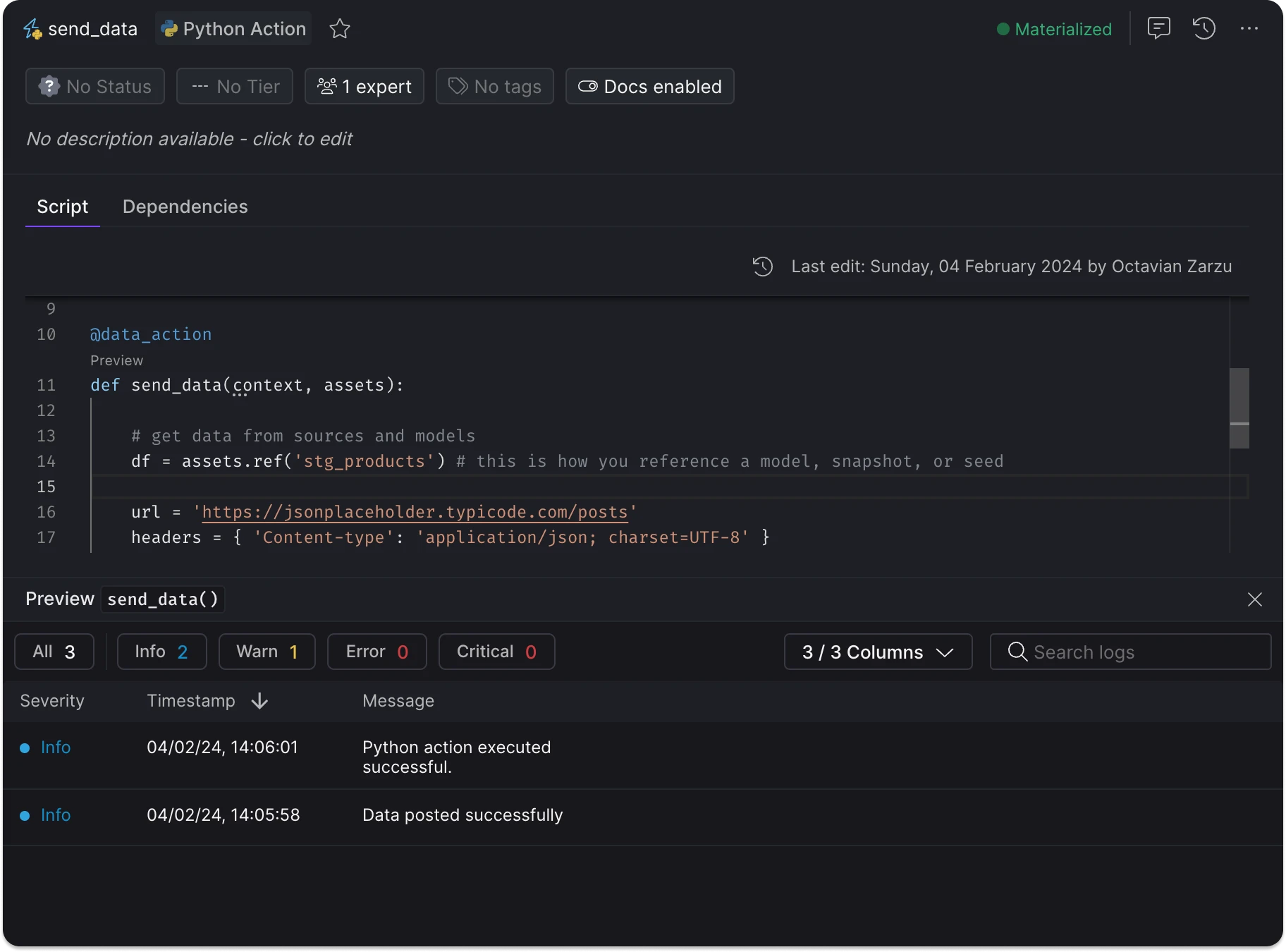
Preview data and logs of any decorated python function.
Lineage integration with script dependencies
Referencing sources and models in your Python script adds them to the Dependencies tab, creating a visible dependency in Lineage mode.
In the lineage view, a link is automatically established between the Python source table and the dbt model.
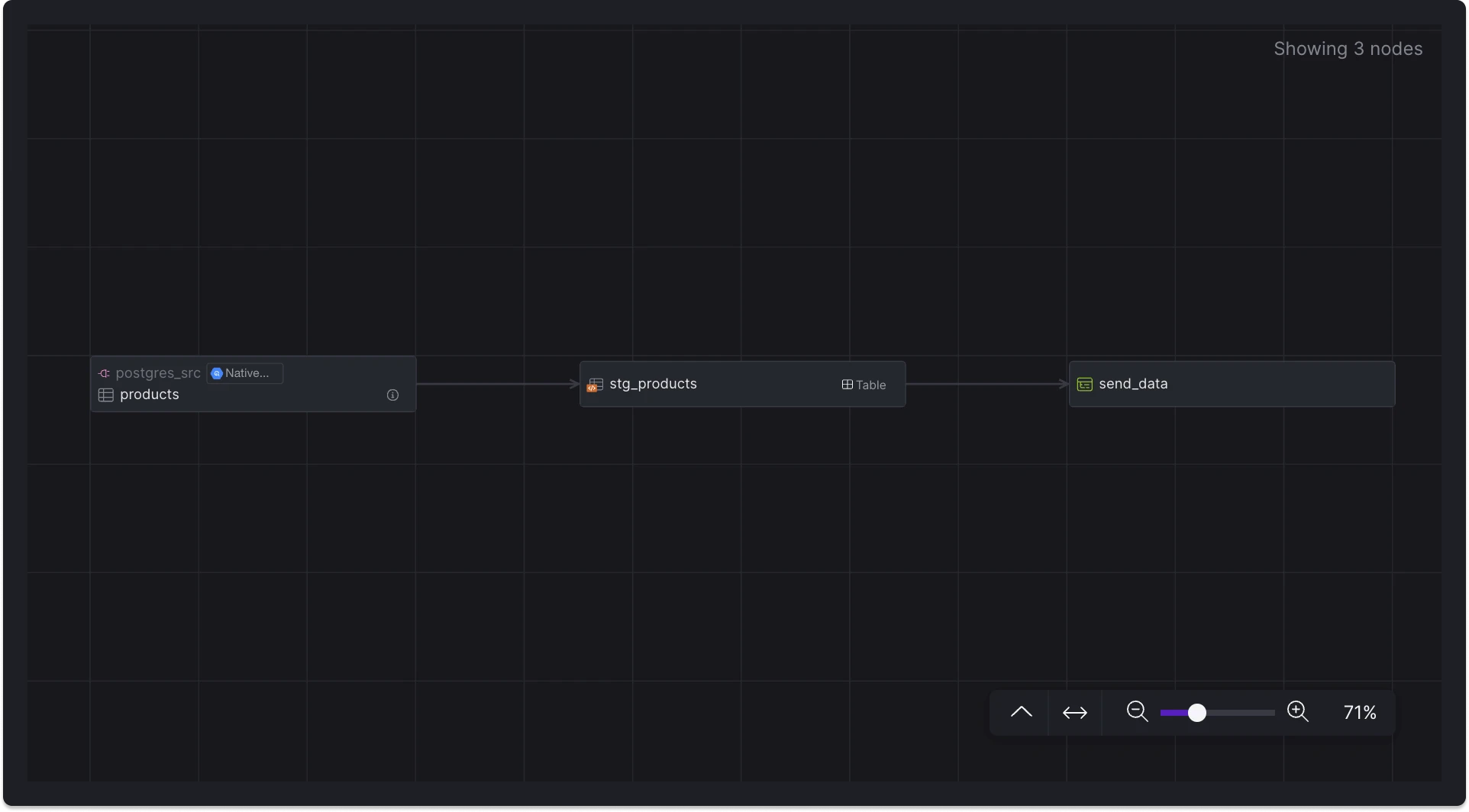
Python actions connected to an upstream SQL model.
Installing custom modules
To install custom modules, list them in a requirements.txt file. Begin by switching to Code mode, then create or edit the requirements.txt located in the python_actions folder.
- send_data.yml
- send_data.py
- requirements.txt
Example of requirements.txt file content:
FAQ
What should I do if my asset is not found and I can't run jobs?
If you encounter an issue where your asset cannot be found, preventing you from running jobs, the first step is to verify the location of the exposure YAML file in Code mode. Ensure that the file is saved in the correct folder.
Next, check if this folder has been added to the dbt_project.yml file under the model-paths configuration. Misplacement of the YAML file or its absence from the model-paths list in dbt_project.yml can lead to assets not being recognized by the system.
dbt_project.yml example:
Will changes in a branch affect production if I don't update hardcoded IDs or API endpoints?
When you create a branch and modify the code, it's important to note that your changes could still interact with the production destination if you haven't updated the settings accordingly. For instance, if your Python action script in the main branch is configured to trigger a sync in Hightouch using a specific sync ID, and you create a branch to alter this script without changing the sync ID, running the code in your new branch will still initiate the sync in the production environment.
To avoid unintended interactions with your production destination, always ensure to review and adjust the settings, such as sync IDs or API endpoints, when working in a branch. This helps maintain the integrity of your production data and operations, ensuring that development or testing activities do not impact your live environment.
Why do I need to commit after updating dependencies?
Committing changes after updating dependencies is essential for correctly linking the new dependencies in the exposure YAML file. To ensure that all references are properly connected and function as expected, always commit after making changes to the asset dependencies.
I encountered the following exception: y42.v1.exceptions.RefNotFound. How can I resolve it?
If you see this error, it indicates a problem with dependencies:
- Ensure that all references are correctly synchronized in the Dependencies tab.
- Check if the upstream dependency has been built. It must have been built successfully at least once.
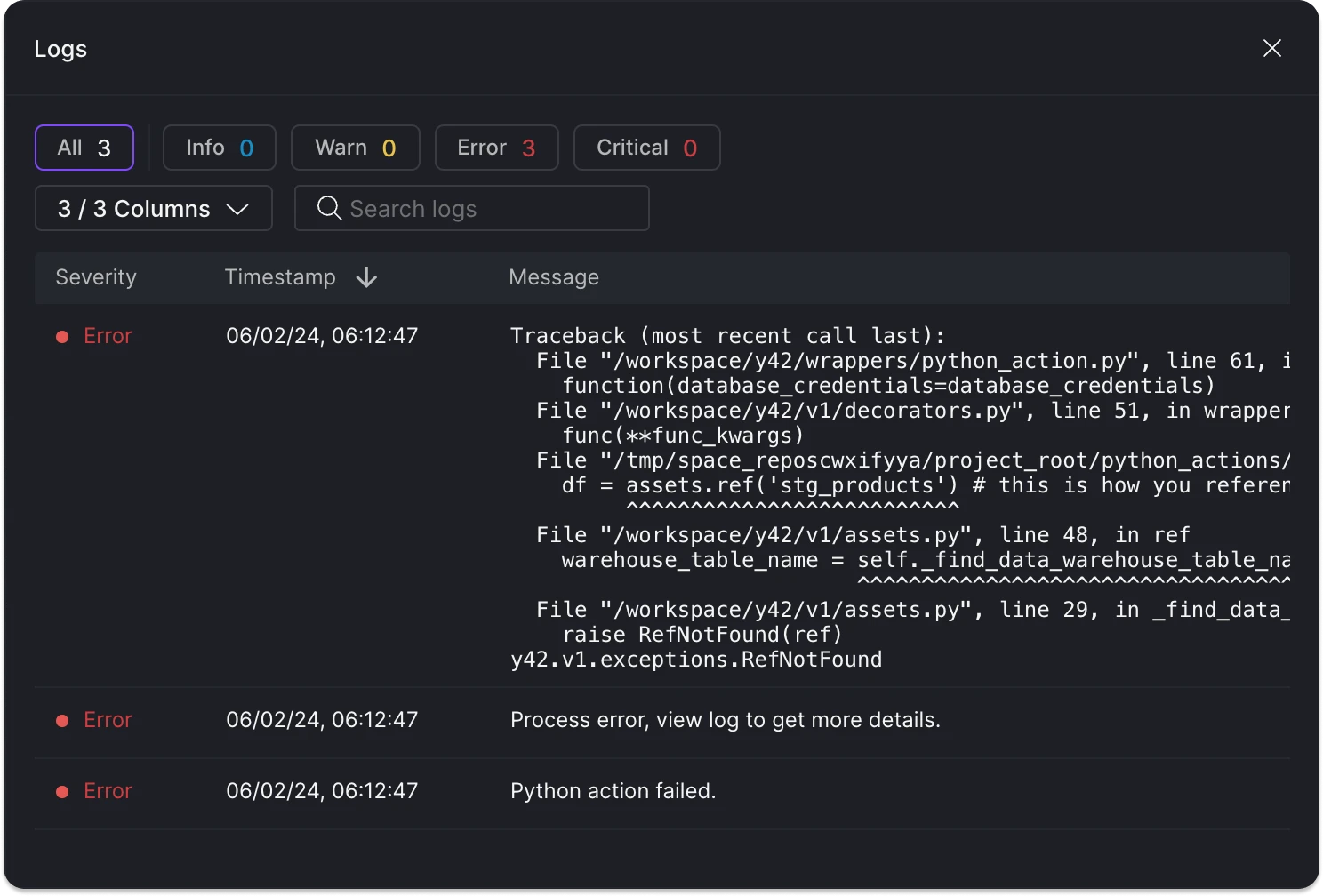
Python Action reference error.