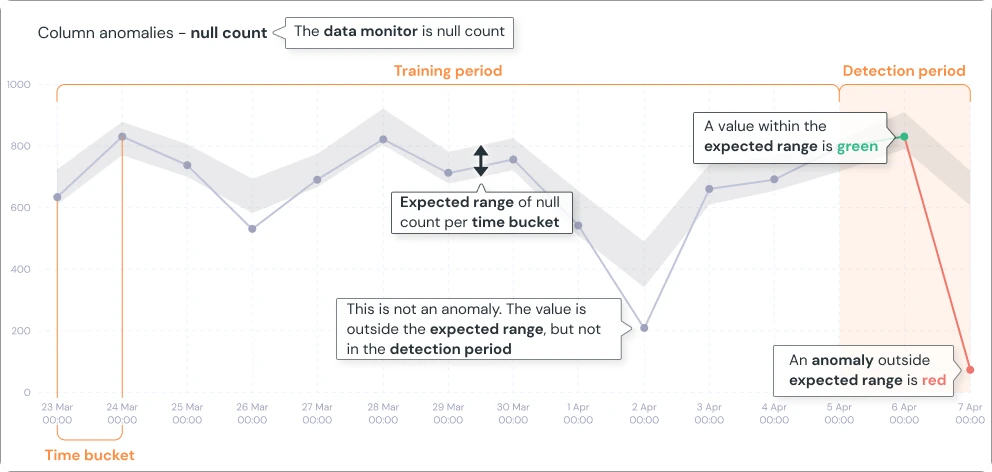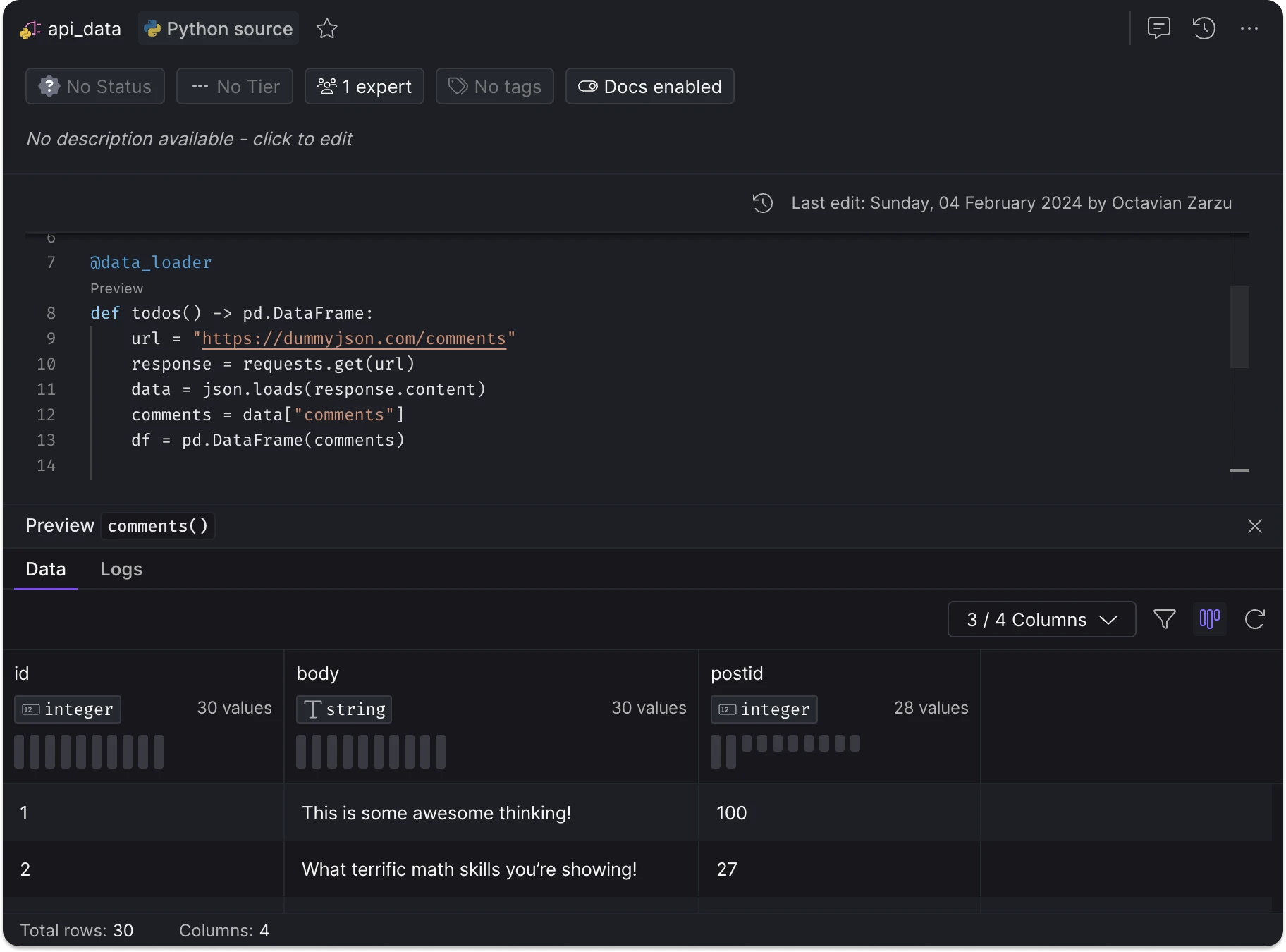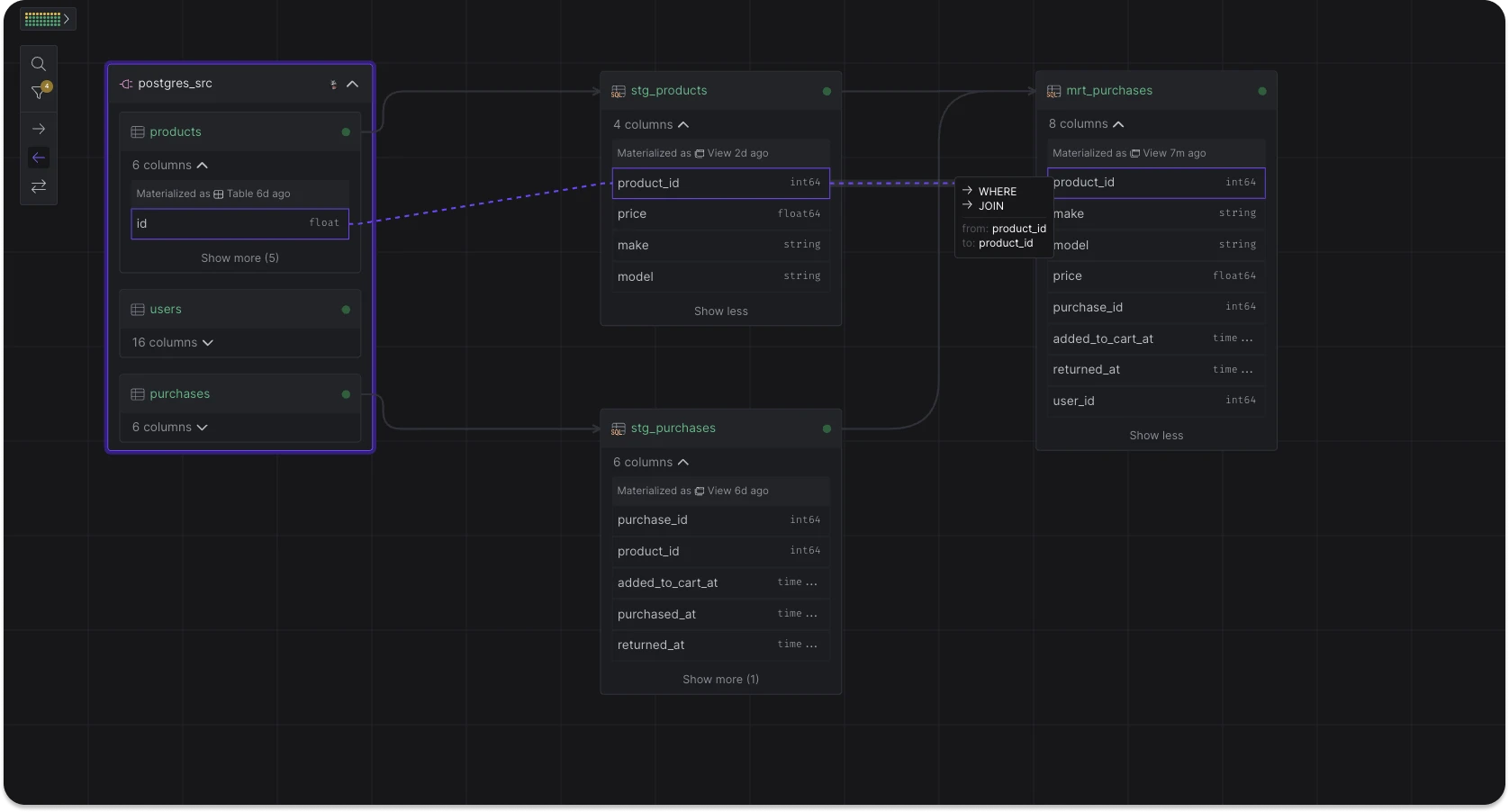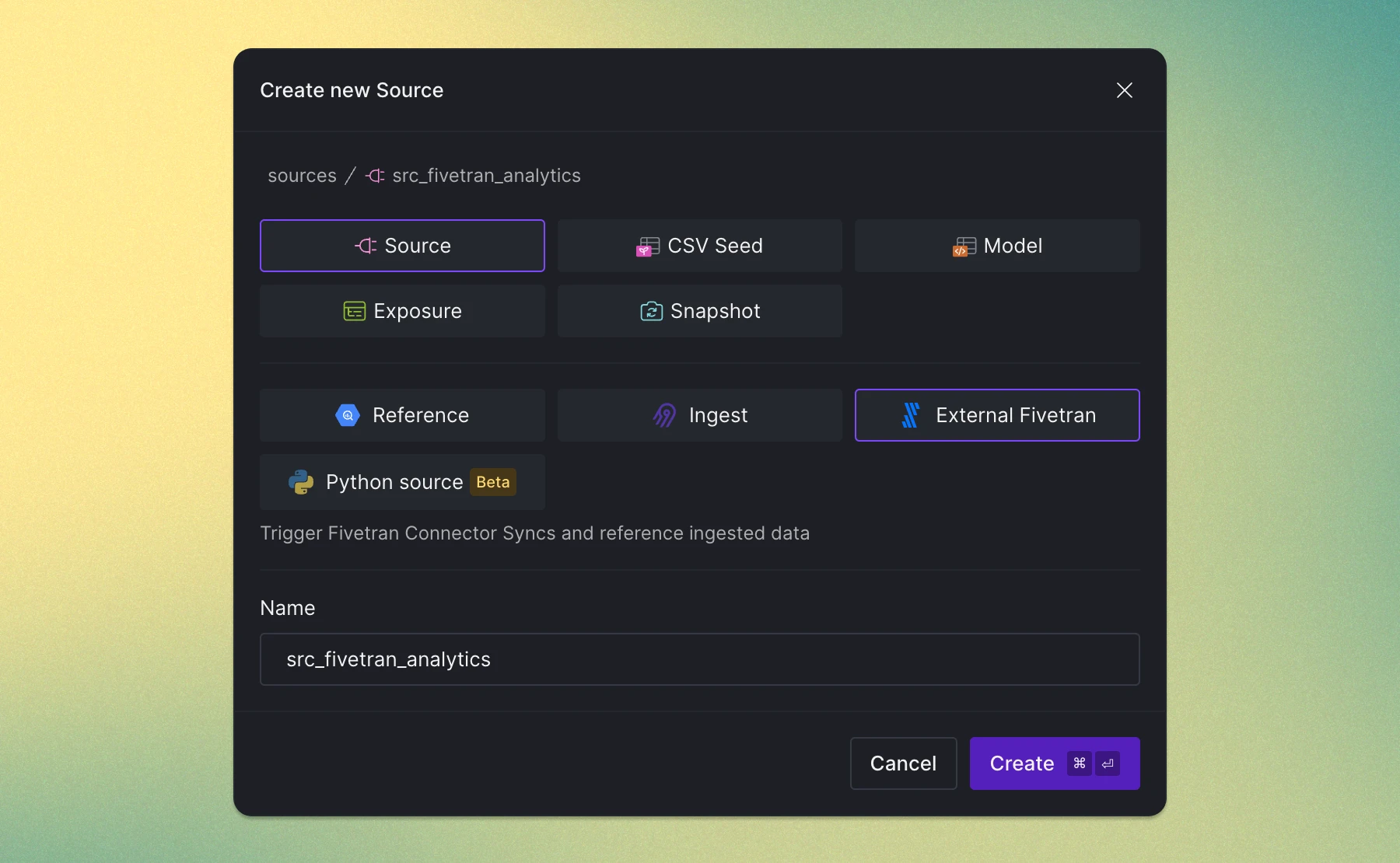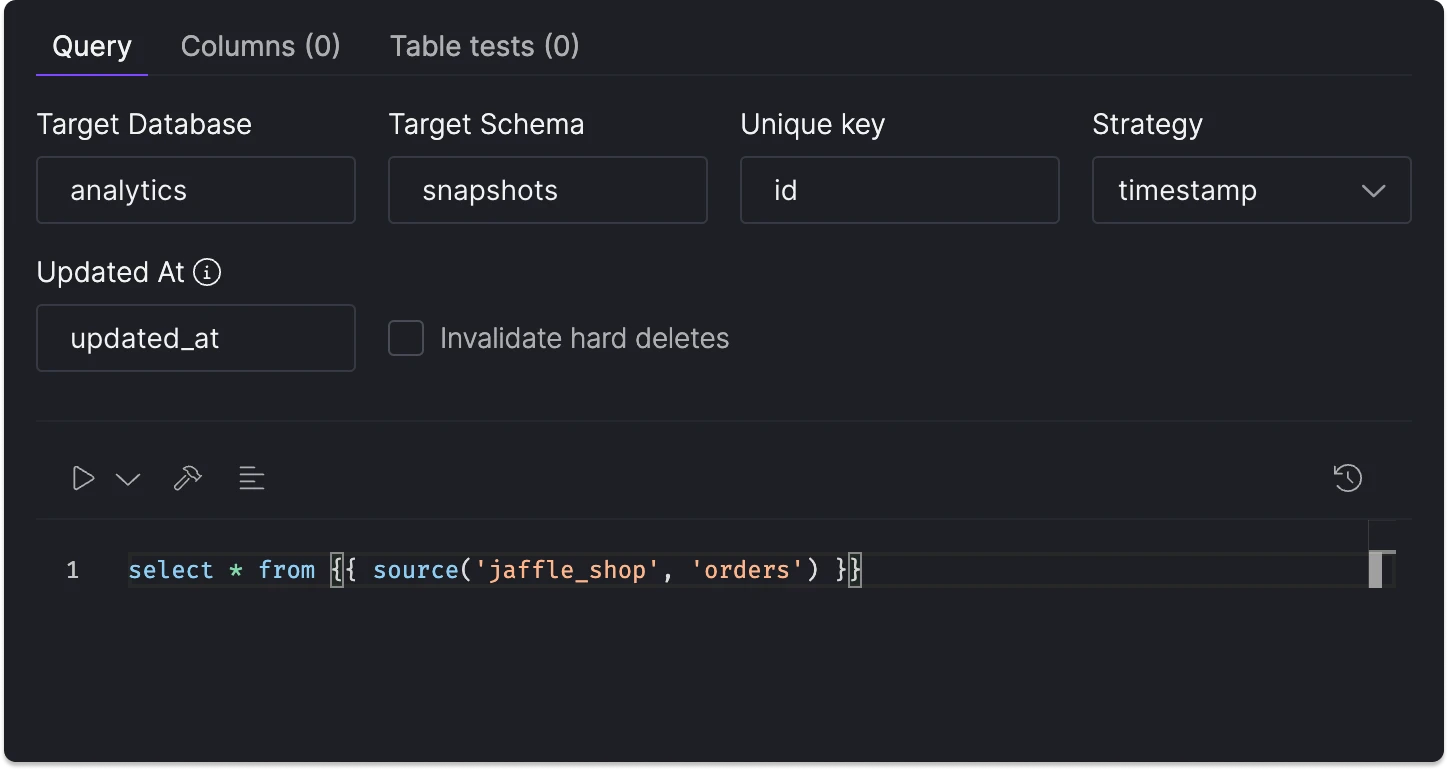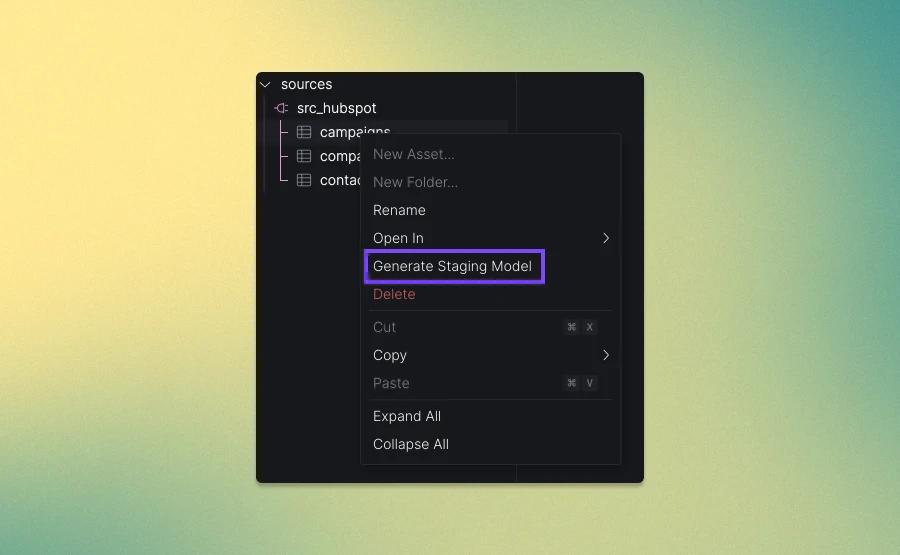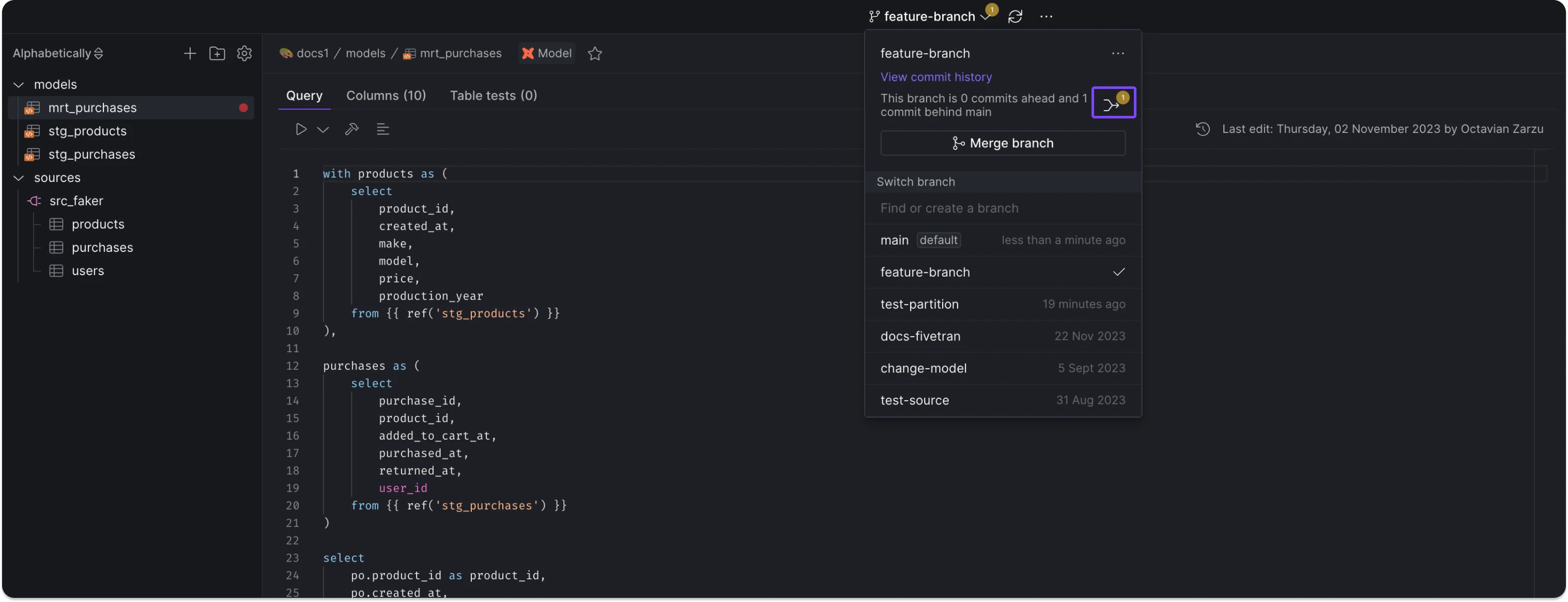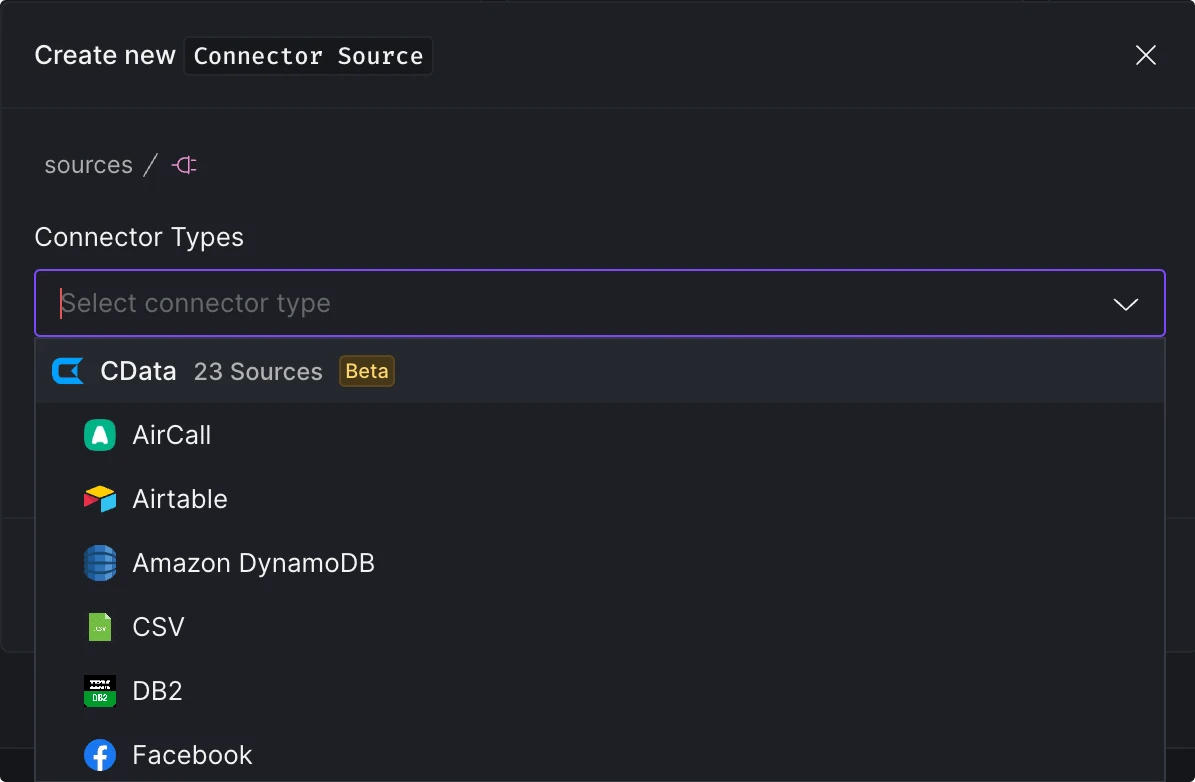
The CData connectors enable ingestion from databases & data warehouses, cloud & SaaS applications, flat files, and unstructured data sources, among others.
ℹ️ Please note that the CData connectors feature is currently in Beta and available for use. As we continue to refine and improve this feature, we encourage users to provide feedback on their experience. Keep in mind that during the beta phase, you may encounter unexpected behavior or changes.
We are rapidly expanding our data source coverage with the CData Connectors. The following are currently supported and ready to use: